Dans l’article précédent j’ai dit que pour certaines pages le script ne trouve pas la fréquence du motif. J’ai trouvé plusieurs raisons pour ça:
- Certaines adresses URL sont protégés et on peut pas récupérer son contenu => on supprime ce lien;
- Pour d’autres pages, le programme récupère bien le dump-text mais la fréquence du motif est 0. Effectivement, c’est le problème de l’expression régulière créée => on la modifie pour rendre plus générale, mais pas restraint:
MOTIF=\bteen\w*\b|\badol\w*\b|\bados?\b|подрост\w*\b
Cette expression nous permet de récupérer les mots qui commence par « teen »+la suite (pour teenager), « adol »+la suite (pour adolescence+adolescent et pour éviter le mot « adopted » en anglais), « ados » (pour les variantes comme « ado.s ») et enfin la racine du mot en russe.
Après avoir fait ces modifications, on a plus de problèmes pour récupérer le contexte et la fréquence du motif.
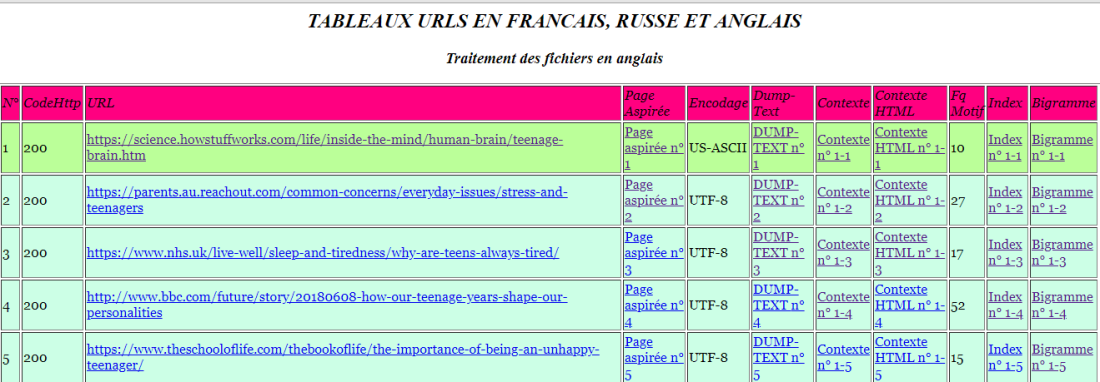
Je souhaitais rendre mon script plus joli: notemmant, la police, avoir le titre général de la page, le titre de chaque tableau qui précise la langue des urls et surtout les couleurs différents qui permettent de savoir par quel moyen on a récupéré l’encodage (sur la page en ligne, sur la page aspirée, etc).
Au final, on obtient:
Il reste de faire la concaténation des fichiers texte et je peux passer à l’analyse linguistique du corpus.
NK
