Bonjour!
Aujourd’hui, je vais décrire ce que j’ai fait le dernier temps avec le script: les dernières colonnes du tableau avec l’information sur le contexte, la fréquence, les bigrammes et l’index des mots recherchés. Toute l’information est récupérée à partir des fichiers « DUMP-TEXT ».
#Contexte
Pour extraire le contexte des mots du projet nous utilisons la commande « egrep -i » (permet de ne pas tenir compte à la case) à laquelle on fournit l’argument ($3) – les mots du projet. Dans l’execution du script sur cygwin ça correspond à:

#Fq motif
Pour savoir la fréquence des mots recherchés sur une pagé html récupéré on utilise « egrep -coi » (ce qui correspond à « c » pour compter; « o » pour le motif; « i » pour ignorer la case) et on stocke le résultat de cette fonction dans une variable, pour que le résultat soit affiché dans notre tableau.
#Index
« egrep -o » est une commande qui écrit sur les lignes séparés les lignes correspondant à la recherche. Pour rechercher tous les mots dans une page l’argument de cette fonction est une expression régulière: « \w+ ». Ensuite on applique les commandes: « sort » qui sert à trier les lignes, « uniq -c » qui compte le nombre d’occurences et « sort -r » qui affiche l’ordre inverse du résultat de ces commandes.
#Bigrammes
Pour créer les bigrammes on stocke les mots de la page dans un fichier « temporaire », à ce fichier on applique la commande « tail -n +2 » pour faire la même liste à partir du 2ème mot de la 1ère liste et on garde le résultat dans un autre fichier « temporaire ». Ensuite, on colle les deux fichiers et pour trier le résultat on applique la même procédure que celle pour la création d’index.
#Contexte html
Pour la création du contexte html, on a utilisé le programme « minigrep » muni par Serge Fleury. Ce programme filtre des fichiers multilingues. En entrée il prend le fichier du dump-text et le motif recherché, en sortie on a le fichier html avec le contetxe du motif.
#Problèmes avec Perl
Pour exécuter le script sur Perl, j’ai téléchargé la dernière version de l’environnement Perl Strawberry 5.28, mais j’arrivais pas à lancer le programme:
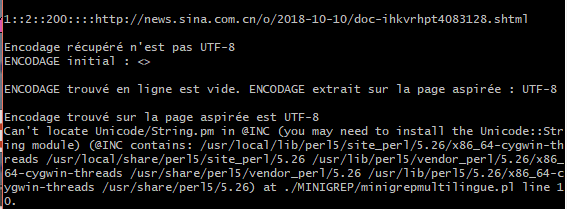
J’ai donc essayé de résoudre ce problème de la façon suivante: dans la fenêtre de commande Windows j’ai appelé « cpan Unicode::String » pour installer l’utilitaire cpan nécessaire pour minigrep et une fois l’installation a été fini j’ai fait appel au programme sur cygwin. Cette méthode n’a pas résolu le problème, j’ai donc décidé de préciser dans le script quelle version de perl il faut employer, en espérant que ça marche. Cela ne m’a pas aidé non plus, j’ai désinstallé Perl et j’ai installé la version 5.16.3. J’ai refait les mêmes étapes pour cette version et ça a marché. Apparemment, le minigrep et la dernière version de Perl ne sont pas compatibles sur ma machine.
Au final, le script de la création du tableau est le suivant:
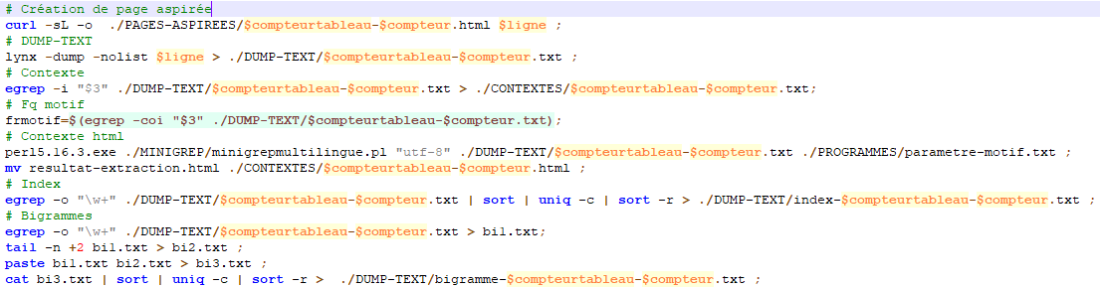
On répète quasi-mêmes étapes pour tous les niveaux d’extraction de l’encodage.
Dans une autre article j’ai mentionné que j’arrive pas à faire le transcodage des pages qui ne sont pas en UTF-8. En effet, la fonction « iconv » fait le transcodage du « DUMP-TEXT » et pas de la page, donc c’est normal que dans le tableau dans la collone « Encodage » j’ai l’encodage récupéré de la page. « iconv » crée un nouveau fichier du dump-text qui est convertit en UTF-8.
#Problèmes avec la Fq motif
Quand j’ai crée mon tableau, il y a certains liens pour lesquels le script ne trouve pas la fréquence du motif (et donc il n’y a pas de contexte pour ces liens). Trouver d’où vient ce problème.

NK
