Bonjour!
Notre projet avance et on constate certains problèmes apparaître. Ainsi, le script écrit jusqu’à cette séance a bien récupéré l’encodage des pages:

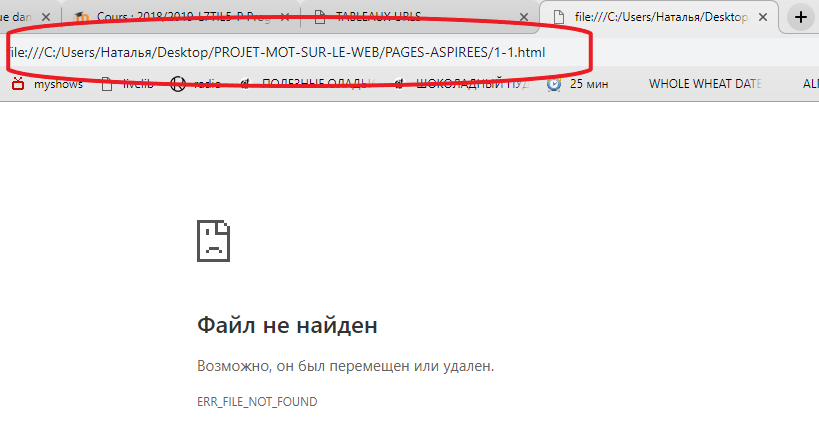
Mais les pages n’ont pas été aspirées, si on clique dessus on a le message que ce fichier n’existe pas, même si le script marche bien (l’adresse de la page indique bien l’emplacement du fichier) :
La nouvelle version du script ne récupère plus l’encodage des pages, même s’il est en UTF-8 (si on va directement sur la page et on cherche l’encodage dans le code html, on trouve ‘charset = UTF-8’), ni crée pas l’aspiration des pages :

Donc le but de cet article est d’essayer de trouver la solution à ce problème.
D’abord, on cherche le problème du code pour récupérer de l’encodage. Quand on a refait du zéro le code, nous avons réussi à remplir le tableau par des liens qui sont encodés en UTF-8 et nous avons aussi créé les pages aspirées (c’était donc une faute de frappe). Par contre, il y a certaines pages qui ne son pas publiées dans notre tableau, même si leur encodage est « utf-8 »:

En cours nous avons discuté la solution à ce problème (par étape):
- La première requête nous envoie la chaîne vide: on cherche l’encodage à l’aide de commande « file -i » sur la page aspirée.
- L’encodage récupéré UTF-8 ou non ? Si oui, on procède juste au traitement, si non on vérifie avec « iconv » si cet encodage est connu par la commande et on fait le transcodage.
- Si l’encodage n’est pas connu: on peut plus rien faire.
____________________________________________________________________________________________
La nouvelle commande:
iconv – permet de changer l’encodage d’un fichier: iconv -f code_base -t nouveau_code entree -o sortie
____________________________________________________________________________________________
Après les tours de magie, la seule chose que nous avons réussi à améliorer: le tableau affiche maintenant tous les liens: « utf-8 » (nous avons essayé de modifier la capitalisation de l’encodage récupéré par « file -i » mais le script ne l’affiche pas le résultat) et d’autres liens avec l’encodage qu’il faudra transcoder:

De plus, pendant le déroulement du script, j’ai remarqué le message de cygwin « ligne 38: commande introuvable », ce qui correspond à la commande « lynx » => les fichiers « dump » sont vides, même si elles existent.
____________________________________________________________________________________________
Cet article est écrit plutôt pour nous aider à éclairer les choses, qu’on a fait jusqu’à présent. Qu’est-ce qu’il faut faire?
- télécharger le package « lynx » sur cygwin;
- continuer à chercher comment transcoder les encodages qui ne sont pas « UTF-8 »;
- capitaliser « utf-8 » qui a été récupéré par « file -i ».
Quand ce sera réglé, on pourra continuer à remplir le tableau avec bigrammes, contextes, etc.
